
Wir verlassen das Zeitalter der eindimensionalen Künstlichen Intelligenz (KI). Während die ersten Jahre der KI-Revolution von reinem Textverständnis geprägt waren, bricht 2026 eine neue Ära an: Die Ära der Multimodalen KI.
Diese neuen Systeme begreifen die Welt wie wir Menschen es tun. Sie verarbeiten Bild, Ton und Text gleichzeitig. Für Unternehmen bedeutet das den Sprung von einfachen Chatbots hin zu autonomen Assistenten, die komplexe Geschäftsprozesse visuell und auditiv steuern können.
In diesem Artikel analysieren wir die führenden Modelle und zeigen auf, wie B2B-Entscheider die Grenze zwischen reiner Datenverarbeitung und kontextueller kognitiver Analyse neu definieren.
Multimodale KI einfach erklärt
Lange Zeit war Künstliche Intelligenz „spezialisiert“: Ein Modell konnte Texte schreiben, ein anderes Bilder erkennen. Multimodale KI bricht diese Silos auf. Sie ermöglicht es einem System, verschiedene Datentypen – sogenannte Modalitäten – nicht nur parallel zu verarbeiten, sondern sie in einem ganzheitlichen Kontext zu interpretieren.
Das macht den entscheidenden Unterschied: Eine multimodale KI liest nicht nur das Handbuch einer Maschine (Text), sondern sieht gleichzeitig das Live-Video der Wartungskamera (Bild) und hört z.B. das unregelmäßige Geräusch des Motors (Audio).
Erst durch die Kombination dieser verschiedenen Eindrücke kann die KI die Situation wirklich verstehen.
Was bedeutet „Modalität“ in der Praxis?
In der Welt der KI steht „Modalität“ für die verschiedenen Kommunikations- und Datenwege. Die wichtigsten Kanäle sind:
- Text: Das geschriebene Wort, Programmiercodes oder Dokumente.
- Visuelle Daten: Fotos, Infografiken und technische Zeichnungen.
- Audio: Gesprochene Sprache, Geräuschkulissen oder Frequenzen.
- Video: Die zeitliche Abfolge von Bildern kombiniert mit Ton.
- Sensorik & Metadaten: In der Industrie 4.0 fließen hier Messwerte wie Temperatur, Druck oder GPS-Daten ein.
Der Clou: Ein multimodales System arbeitet nicht wie eine Kette von Einzelwerkzeugen, sondern wie ein zentrales Gehirn. Es verknüpft die Modalitäten so eng miteinander, dass es beispielsweise eine Video-Szene beschreiben kann (Video-zu-Text) oder aus einer Skizze und einer mündlichen Anweisung einen fertigen Software-Code generiert.
Hinter den Kulissen: Wie lernt KI das „Zusammensetzen“?
Technisch gesehen basiert multimodale KI auf hochkomplexen neuronalen Netzen, die Informationen nicht nur linear, sondern über verschiedene Eingangskanäle gleichzeitig verarbeiten. Man kann sich diesen Prozess wie ein Orchester vorstellen, bei dem verschiedene Instrumente (Daten) von einem Dirigenten (dem Modell) zu einer harmonischen Symphonie zusammengeführt werden.
Die Architektur besteht im Wesentlichen aus drei Säulen:
- Spezialisierte Encoder (Die Eingangskanäle): Anstatt eines einzelnen Netzes nutzt das System spezialisierte „Experten“ für jede Datenart. Ein Vision-Transformer analysiert Pixelstrukturen in Bildern, während ein Large Language Model (LLM) die Semantik von Texten entschlüsselt. Jeder Datentyp wird zunächst in eine mathematische Form übersetzt, sogenannte Embeddings.
- Das Fusionsmodul (Die kognitive Schnittstelle): Dies ist das Herzstück. Hier findet das sogenannte Alignment statt, d.h. die KI bringt alle Informationen (Text, Bild und Ton) an einen Tisch. Sie gleicht die verschiedenen Datenströme so ab, dass keine Missverständnisse entstehen. Das System versteht dann z.B., dass das geschriebene Wort ‚Stopp‘ exakt zu dem visuellen Reiz des roten Schildes auf der Straße gehört. Erst durch diesen Abgleich entsteht aus reinen Daten echtes, kontextbezogenes Wissen.
- Das Dekodermodul (Die ganzheitliche Ausgabe) Nach der Analyse generiert das System eine Antwort, die weit über Text hinausgehen kann. Das Ergebnis ist kontextsensitiv: Die KI kann eine Grafik erstellen, die genau den geschriebenen Inhalt erklärt, oder ein Video basierend auf einer Audio-Beschreibung generieren.
Der Vorteil gegenüber klassischen Systemen: Während ein reines Text-Modell nur „weiß“, was ein Apfel ist, weil es darüber gelesen hat, „versteht“ ein multimodales Modell die Beschaffenheit, das Aussehen und vielleicht sogar das Geräusch beim Hineinbeißen. Dieses situative Verständnis ist der Schlüssel für die Anwendungen von morgen.
Top Multimodale KI-Modelle 2026: GPT-5, Gemini 3, Llama 4
Im Jahr 2026 ist Multimodalität bereits zum Standard geworden. Dennoch unterscheiden sich die Top-Modelle massiv in ihrer Architektur und ihrem Fokus. Während einige auf maximale Rechenpower setzen, konzentrieren sich andere auf Effizienz und lokale Ausführung.
OpenAI: Die GPT-5 Ära & „Omni-Intelligence“
OpenAI hat mit der GPT-5 Serie die Grenze zwischen Mensch und Maschine weiter verwischt:
- Agentic Reasoning: Das Modell kann nicht nur Bilder beschreiben, sondern aktiv in visuellen Oberflächen navigieren (z. B. ein Software-Interface bedienen).
- Echtzeit-Audio: Die Latenz bei Sprachinteraktionen ist praktisch verschwunden, was GPT-5 zum idealen Partner für Echtzeit-Übersetzungen und emotionale Kundenberatung macht.
- Fokus: High-End-Anwendungen, die tiefes logisches Verständnis über Text, Bild und Code hinweg erfordern.
Google: Gemini 3 & das Ökosystem-Wunder
Google nutzt seinen Vorsprung bei Video-Daten (YouTube) und Cloud-Infrastruktur voll aus. Gemini 3 gilt 2026 als das leistungsfähigste Modell für multimediales Reasoning.
- Massive Context Windows: Mit einem Kontextfenster von über 2 Millionen Tokens kann Gemini stundenlange Videodateien oder riesige technische Dokumentationen in einem Durchgang analysieren.
- Native Video-Analyse: Im Gegensatz zu Modellen, die nur Einzelbilder extrahieren, versteht Gemini zeitliche Abläufe und Kausalitäten in Videos nativ.
- Fokus: Enterprise-Lösungen, komplexe Datenanalyse und tiefgehende Recherche-Aufgaben.
Meta: Llama 4 – Die Open-Source-Revolution
Mit der Llama 4-Serie (Modelle wie Maverick und Scout) hat Meta bewiesen, dass Spitzenleistung auch „offen“ sein kann.
- Effizienz durch MoE: Dank der Mixture-of-Experts-Architektur sind die Modelle extrem schnell und ressourcensparend, was sie für Edge-Computing und lokale Server attraktiv macht.
- Native Multimodalität: Llama 4 wurde von Grund auf multimodal trainiert, wodurch die Verknüpfung von Bild- und Textinformationen deutlich präziser ist als bei nachträglich „angestückelten“ Lösungen.
- Fokus: Anpassbare Enterprise-Lösungen, On-Premise-Hosting und Forschung.
Anthropic: Claude 4 & ethische Präzision
Claude 4 hat sich 2026 als das sicherste und präziseste Modell für geschäftskritische Dokumente etabliert.
- Computer Use: Claude kann virtuelle Computerumgebungen steuern, um komplexe Workflows autonom auszuführen.
- Visuelle Genauigkeit: Besonders stark bei der Analyse von Tabellen, Charts und technischen Zeichnungen. Ein entscheidender Vorteil für Ingenieure und Analysten.
Multimodale KI in der Praxis: Wo Theorie auf Wertschöpfung trifft
Im Jahr 2026 hat die multimodale KI die Experimentierphase verlassen. Sie ist heute das Herzstück geschäftskritischer Anwendungen, die von der Millisekunde in der autonomen Fahrt bis hin zur langfristigen medizinischen Therapie reichen.
Gesundheitswesen: Der „Patient 360“-Ansatz
Multimodale Modelle haben die Diagnose revolutioniert. Statt isolierter Daten betrachten Systeme heute das Gesamtbild:
- Ganzheitliche Diagnose: Eine KI analysiert gleichzeitig die radiologischen Bilder (CT/MRT), die elektronische Patientenakte (Text) und genetische Marker.
- Vorteil: Durch dieses „Alignment“ werden Krankheiten wie Hautkrebs oder Kardiomegalie (vergrößertes Herz) oft früher erkannt als durch eine rein menschliche Sichtung.
- B2B-Impact: Kliniken nutzen multimodale Assistenten (wie Googles AMIE), um die Zeit für die Dokumentation zu halbieren und die Behandlungsqualität zu steigern.
Mobilität: Sensorfusion in Echtzeit
Für autonomes Fahren ist Multimodalität lebensnotwendig. Fahrzeuge müssen 2026 nicht nur „sehen“, sondern auch verstehen.
- Daten-Symbiose: Kameras, LIDAR, Radar und akustische Sensoren werden synchron verarbeitet. Die KI erkennt nicht nur ein Hindernis, sondern ordnet durch die Kombination von Bild und Schall (z. B. ein herannahendes Martinshorn) die Situation korrekt ein.
- Robuste Navigation: Selbst bei schlechter Sicht (Nebel/Regen) kompensiert die Fusion der verschiedenen Sensorkanäle die Schwächen einzelner Modalitäten.
Industry 4.0 & Robotics
In der modernen Fertigung ermöglicht die „Physische KI“ eine neue Stufe der Automatisierung:
- Interaktive Roboter: Kollaborative Roboter (Cobots) verstehen heute natürliche Sprache, interpretieren menschliche Gestik und reagieren auf taktile Sensoren.
- Lagerlogistik: Roboter navigieren autonom durch dynamische Umgebungen, indem sie visuelle Karten mit Echtzeit-Telemetriedaten abgleichen.
Inklusion & Barrierefreiheit: Die „Goldene Ära“ des Zugangs
Multimodale KI fungiert 2026 als universeller Übersetzer für menschliche Sinne:
- Scene Description: Sehbehinderte Menschen nutzen Smart Glasses, die ihre Umgebung in Echtzeit beschreiben („Ein rotes Auto nähert sich von links“).
- Adaptive Interfaces: Benutzeroberflächen passen sich automatisch an die Fähigkeiten des Nutzers an, von Sprache-zu-Text bis hin zur intuitiven Gestensteuerung.
Marketing & Content-Produktion
Die kreative Industrie nutzt Multimodalität für hocheffiziente Workflows:
- Text-to-Video: Werbekampagnen werden per Prompt erstellt, wobei die KI Regieanweisungen (Text), Sound-Design (Audio) und visuelle Ästhetik (Video) perfekt aufeinander abstimmt.
Marktpotenzial: Die „Omni-Standard“-Ära bis 2030
Wir befinden uns 2026 an einem Wendepunkt. Experten prognostizieren eine massive Beschleunigung des Marktes, da die Technologie nun tief in produktive Geschäftsprozesse integriert ist.
Marktwachstum und Prognosen
Die Zahlen sprechen eine deutliche Sprache:
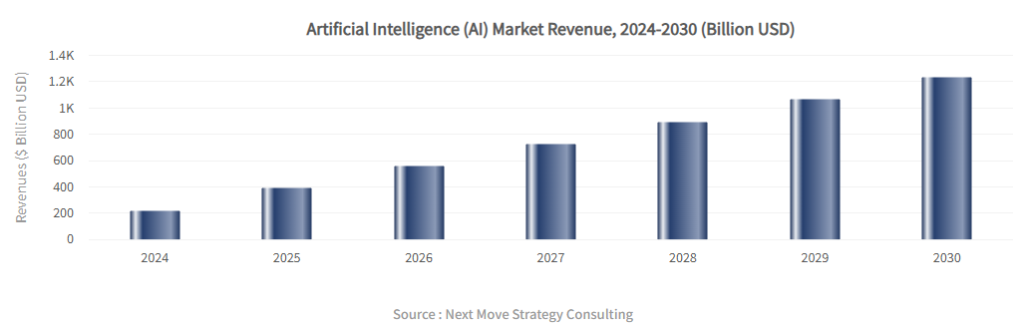
- Standardisierung: Analysten (wie Gartner) erwarten, dass bereits bis 2027 über 40 % der generativen KI-Lösungen multimodal sein werden. Ein gewaltiger Sprung von den damals nur 1 % im Jahr 2023.
- Marktvolumen: Der globale KI-Markt soll bis 2030 auf über 1236,47 Milliarden USD anwachsen, wobei die Fähigkeit zur simultanen Verarbeitung von Text, Bild und Audio der Haupttreiber für neue Software-Investitionen ist.
- Branchenführer: Besonders im Gesundheitswesen und in der industriellen Robotik wird Multimodalität zur Kernvoraussetzung.
Zukünftige Entwicklungen: Was kommt nach 2026?
Die Entwicklung bleibt nicht beim bloßen „Verstehen“ stehen. Die Trends der nächsten Jahre sind:
- Vom Chatbot zum Agenten (Agentic AI): KI-Systeme werden autonomer. Sie nutzen ihre multimodale Wahrnehmung, um eigenständig mehrstufige Aufgaben in Unternehmenssoftware auszuführen: Sie „sehen“ den Desktop, „hören“ Anweisungen und „schreiben“ Berichte.
- Small Language Models (SLMs) auf dem Device: Der Trend geht weg von riesigen Cloud-Modellen hin zu hocheffizienten, multimodalen Modellen, die direkt auf dem Smartphone oder dem Industrieroboter laufen – schneller, günstiger und datenschutzkonform.
- Wissenschaftliche Entdeckung: KI wird 2026 zum aktiven Partner in der Forschung. In der Biologie und Chemie analysiert sie mikroskopische Bilder, molekulare Daten und Forschungsarbeiten gleichzeitig, um neue Materialien oder Medikamente zu designen.
Das Fazit für Entscheider: Wer heute in KI investiert, muss auf Multimodalität setzen! Systeme, die nur eine Datenart verstehen, werden in einer Welt, die aus Bildern, Tönen und Texten besteht, schnell zum technologischen Flaschenhals.
Herausforderungen und ethische Aspekte: Die Leitplanken der Innovation
Trotz des enormen Potenzials bringt die multimodale Revolution 2026 auch komplexe Hürden mit sich. Unternehmen, die diese Technologie strategisch einsetzen, müssen Governance und Ethik als Kernbestandteile ihrer Roadmap begreifen.
Technische Komplexität und Ressourcenbedarf
Multimodale Systeme sind weitaus fordernder als reine Text-KIs.
- Daten-Synchronisation: Die Fusion von asynchronen Datenströmen (z. B. ein hochfrequentes Audio-Signal mit einer niedrigeren Bildrate eines Videos) bleibt eine mathematische Herkulesaufgabe.
- Rechenleistung & Kosten: Das Training und der Betrieb multimodaler Agenten erfordern massive GPU-Ressourcen. 2026 rückt daher die Energieeffizienz in den Fokus, um Nachhaltigkeitsziele (ESG) nicht zu gefährden.
Erklärbarkeit (XAI) und das „Black Box“-Problem
Je mehr Sinneskanäle eine KI verknüpft, desto schwerer ist nachzuvollziehen, warum sie eine bestimmte Entscheidung getroffen hat.
- Trustworthy AI: In hochregulierten Bereichen wie Medizin oder Finanzen fordern Aufsichtsbehörden bis Ende 2026, dass KI-Entscheidungen auditierbar sind. Explainable AI (XAI) wird vom Forschungsthema zum Branchenstandard.
- Bias-Verstärkung: Multimodale Modelle können Vorurteile (Bias) über verschiedene Medien hinweg potenzieren (z. B. wenn eine KI bestimmte Stimmenmuster fälschlicherweise mit negativen visuellen Merkmalen verknüpft).
Datenschutz und der EU AI Act
Die Verarbeitung von Bild- und Tondaten ist hochsensibel.
- Regulatorik: Der EU AI Act ist 2026 voll in Kraft. Unternehmen müssen sicherstellen, dass ihre multimodalen Anwendungen (besonders bei Biometrie oder kritischen Infrastrukturen) die strengen Compliance-Vorgaben erfüllen.
- Datensouveränität: Der Trend geht zu lokalen Modellen (Edge AI). Sensible Daten werden direkt auf dem Gerät oder On-Premise verarbeitet, um das Risiko von Datenlecks in der Cloud zu minimieren.
Experten-Hinweis: Gartner warnt, dass bis 2027 über 40 % der KI-Projekte scheitern könnten, wenn sie ohne klare Governance-Strukturen gestartet werden.
Fazit: Warum multimodale KI Ihr B2B-Business 2026 verändert
Multimodale KI markiert den wohl bedeutendsten Paradigmenwechsel seit der Erfindung des Deep Learnings. Wir verlassen das Zeitalter, in dem Maschinen Informationen in getrennten Silos verarbeiten. 2026 verstehen KI-Systeme die Welt endlich so, wie wir es tun: als ein komplexes Zusammenspiel aus Text, Bild, Ton und Bewegung.
Für Unternehmen gilt: Die Herausforderungen bei Datenschutz und Erklärbarkeit sind real, aber sie sind keine Stoppschilder, sondern Leitplanken. KI darf 2026 nicht mehr als ein isoliertes Werkzeug betrachtet werden. Sie wird zum zentralen Nervensystem, das Informationen über alle Kanäle hinweg verknüpft, analysiert und in wertvolle Handlungen übersetzt.
Die Zukunft der KI ist nicht nur klüger – sie hat endlich Augen und Ohren für die Realität!
Verwandter Artikel: Wie KI Ihr Unternehmen revolutionieren kann



